
前回の記事は全部で2,065文字(!)と、かなり長文になりました。
そのため、一部をかなり端折った感があるので、自分のメモのためにも補足します。
ウェブサイトのソース
(以下Chromeを使用しています。)
ページ上で右クリック→「ページのソースの表示」をクリックします。
ソースが表示されます。
赤い枠で囲んでいる部分に注目します。
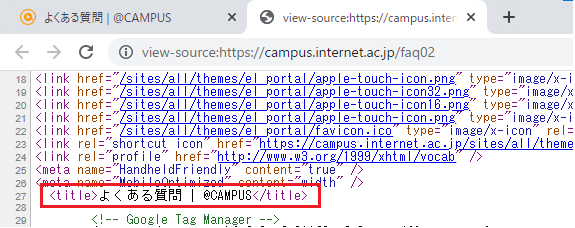
<title>と</title>の間に「よくある質問 | @CAMPUS」という文字列があります。
この<title>と</title>がHTMLのタグです。(titleタグと呼ばれます。)
もし次のようなプログラムを書いて実行すれば、「よくある質問 | @CAMPUS」という文字列を取得することができます。
import requests
from bs4 import BeautifulSoup
url = "https://(URL)"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
print(soup.find("title").text)
1-2行目:
requests・Beautiful Soupを使うためにインポートします。
3行目:
変数urlにアクセスするウェブサイトのURLを代入します。
4行目:
変数responseに、変数urlに代入したURLにアクセス、取得した内容を代入します。
5行目:
変数soupに変数responseの内容=変数urlに代入したURLより取得した内容を解析します。
6行目:
変数soupに代入した内容から、titleタグの内容を取得します。

コメント