
大枠は決まりました。
では、その大枠を図示します。
ざっくりの流れを書いておきます。
全体の流れはこんな感じです。
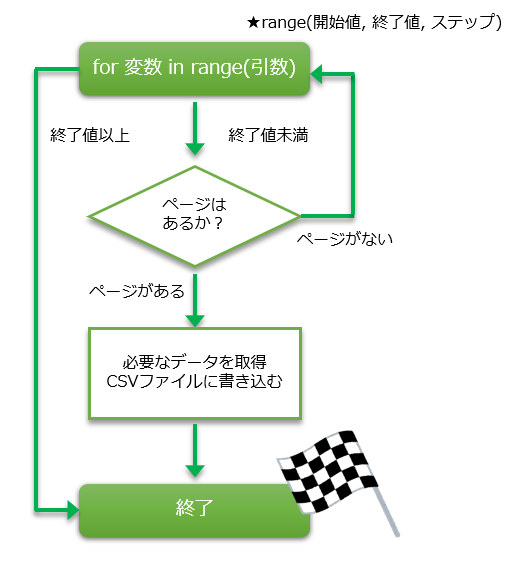
簡単なフローチャートを書くだけで、整理ができますね。
何が必要であるかが理解できれば、あとはプログラムを書くのみです!
Atomを使い、プログラムを書きます。
今回使ってみて、便利だなと思いました。
カッコなどは開始カッコを入れると、終了カッコを自動で入力してくれます。
Pythonでは重要なインデントも自動で制御してくれます。
スクレイピングに使うライブラリをインポート
Pythonではプログラムでライブラリを利用するさい、プログラムの開始でインポートをします。
import requests from bs4 import BeautifulSoup
ウェブページにアクセスするためのrequests、ウェブページから必要なデータを取得するBeautifulSoupを、それぞれインポートします。
作業を繰り返す部分:for文
まず、プログラムの大枠を作ります。
前回の記事で書いたように、URLを構成する数字12桁の最小値から最大値までの間、作業を繰り返します。
そこでfor文を利用します。
————————————————————
for (変数) in range(開始値, 終了値, ステップ)
————————————————————
rangeは関数です。
引数として指定した「開始値」から「終了値」の未満までの整数値を「ステップ」ごとに表示します。
<「終了値」の未満まで>に要注意です。
例えば、開始値=1、終了値=5、ステップ=1の場合、range関数は、1・2・3・4を表示します。
つまり、終了値の指定は、表示したい終了値+1で指定する必要があります。
というわけで、(3)に続きます。

コメント